El código genético es la forma en que se traduce la secuencia de nucleótidos del ARN mensajero (ARNm), a la secuencia de aminoácidos de los polipéptidos que forman las proteínas.
En otras palabras, el código genético marca la correspondencia entre los 20 aminoácidos que forman las proteínas, y los diferentes conjuntos de tres bases (tripletes, denominados codones) que conforman la secuencia de nucleótidos del ARNm, que corresponden a su vez con la información contenida en el ADN de la célula.
Tabla de correspondencias del código genético
El código genético brinda las reglas con las cuales la maquinaria celular utiliza la información genética contenida en el ADN, para que en última instancia se pueda obtener una proteína determinada a partir de dicha información, teniendo al ARNm como intermediario. El mecanismo mediante el cual se transfiere la información contenida en el ADN al ARNm se denomina transcripción. Por su parte, el mecanismo de síntesis de proteínas a partir de la información contenida en el ARNm se denomina traducción. En este último proceso es en donde se ve implicado el código genético.
Las bases nitrogenadas presentes en el ARNm son cuatro: adenina (A), guanina (G), citosina (C) y uracilo (U). Al considerarse en grupos de a tres, se obtiene un total de 64 posibles combinaciones. Cada una de estas combinaciones se denomina codón, y casi todas tienen una correspondencia con un aminoácido de los 20 posibles que forman las proteínas. En el cuadro a continuación, presentamos estas correspondencias que marca el código genético:
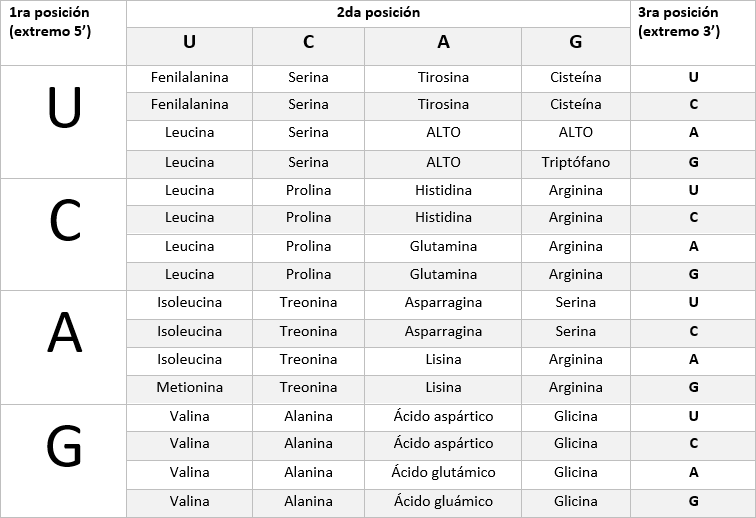
Como ejemplo, podríamos decir que el codón UGC se traduce al aminoácido cisteína, y que el codón ACG lo hace al aminoácido treonina.
Como se habrá notado en el cuadro, las combinaciones de bases UAA, UAG y UGA resultan en un ‘’ALTO’’. Esto quiere decir que dichos codones no se traducen a un aminoácido, sino que marcan el final de la lectura del ARNm, por ende, el final de la proteína en formación. Suelen llamarse ‘’codones de finalización o terminación’’ o ‘’codones sin sentido’’.
Gracias al código genético, somos capaces de predecir la secuencia de aminoácidos que tendrá un polipéptido determinado, conociendo únicamente la secuencia de bases del ARN mensajero que lo codifica.
Características del código genético
El código genético presenta una serie de características, algunas de las cuales se desprenden directamente de la comprensión del cuadro que presentamos en la sección anterior. Dado que todos los tipos de organismos (procariotas y eucariotas) presentan la misma correspondencia entre los codones y los aminoácidos, se dice que el código genético es universal. Sin embargo, existen algunas excepciones que presentan pequeñas variaciones, como son el caso de los cloroplastos, las mitocondrias, y algunos virus, bacterias y levaduras.
Por otra parte, el código genético es degenerado o redundante. Esto quiere decir que hay varios codones diferentes que codifican para un mismo aminoácido. Esto lo vemos en el cuadro de la sección anterior, en donde se observa la repetición de varios de los aminoácidos. Tal es el caso, por ejemplo, de la fenilalanina, que está codificada tanto por el codón UUU como por el UUC. Esta característica es lógica, si consideramos que hay 61 combinaciones posibles de nucleótidos que se corresponden con sólo 20 aminoácidos, y hay sólo tres codones sin sentido.
Por último, cabe destacar que el código genético no presenta ambigüedad, ya que cada codón tiene una correspondencia única con un solo aminoácido.
Referencias bibliográficas
Curtis, H. y Cols. (2022). ‘’Biología en contexto social’’. Octava edición. Buenos Aires: Médica Panamericana.Bertrán C.E & Banús M.C; (1999) ‘’Biología: Transmisión de la Información Genética’’. Argentina. Gráfica Yanel S.A.
Autora
 Escrito por Tatiana Bengochea para la Edición #115 de Enciclopedia Asigna, en 09/2022. Tatiana es Lic. en Ciencias Biológicas y Prof. en Biología. Graduada en la UBA, Arg.
Escrito por Tatiana Bengochea para la Edición #115 de Enciclopedia Asigna, en 09/2022. Tatiana es Lic. en Ciencias Biológicas y Prof. en Biología. Graduada en la UBA, Arg.